[rCore学习笔记 029] 动态内存分配器实现-以buddy_system_allocator源码为例
来源:辣条科技站Gamer发布时间: 2024-10-05 10:10:23
在上一部分,我们讲了动态内存分配器的原理是
维护一个堆
,而且是实现各种
连续内存分配
方法.
但是上一部分是直接通过引用了
buddy_system_allocator
来解决的问题.
那么对于内存分配算法有兴趣的我,还是决定看一下源码,总之
人是咸鱼
但是还是需要有梦想.
人生这么不顺,若是连梦想都没有了,可能当即就找不到活着的意义了吧.
获取buddy_system_allocator的源码
buddy_system_allocator
也是
rCore
这个社区的项目.
cd ~/workspace
git clone https://github.com/rcore-os/buddy_system_allocator.git
从实用的角度开始看源码
为了起一个好头,还是从
比较熟悉
的部分看代码,思考代码是怎么组织的:
buddy_system_allocator
是怎么作为一个外部包被引用的?- 上一部分我们调用了
LockedHeap
,那么这个类是怎么实现的,它依赖于什么?
LockedHeap
我们在源码中搜索
LockedHeap
,我们可以在
lib.rs
里找到它的实现.
pub struct LockedHeap<const ORDER: usize>(Mutex<Heap<ORDER>>);
在看到这个定义的时候有一种
似懂非懂
的感觉,只能
猜到
LockedHeap
是一个加了线程锁的大小为
ORDER
的
Heap
:
- 因为
ORDER
放在了
<>
中间,应该是和
泛型
有关系,但是这里又明确标注了
usize
说明
ORDER
是一个变量.- 因为在结构体的实现中出现了
()
有点不知所云
元组结构体
查看
Rust圣经
,发现确实存在这种字段可以没名称的结构体.
这里又产生了一个新的疑问,如果字段可以没名称,那么
怎么去访问结构体内容
呢?
查阅
Rust语言官方参考手册
,可以看到:
Tuple structs are similar to regular structs, but its fields have no names. They are used like tuples, with deconstruction possible via
let TupleStruct(x, y) = foo;
syntax. For accessing individual variables, the same syntax is used as with regular tuples, namely
foo.0
,
foo.1
, etc, starting at zero.
通过
数字
来访问这些结构体内容.
// 假如存在TupleStruct这个结构体
let foo = TupleStruct(1,2);
// 可以通过这种方法来进行析构
let TupleStruct(x, y) = foo;
// 可以用数字访问
let x = foo.0;
let y = foo.1;
值泛型
那么这里就需要查看
参考书目-值泛型
的内容尤其是它的
示例
.
最终得到结论:Rust是允许使用值的泛型的,这代表
LockedHeap
有一个和值相关的泛型参数.
在某些时候是很像
C
里边的
#define ORDER 0x30000
的.
但是事实上在Rust里是灵活了非常多的.
这和
LockedHeap
提供的两种获取示例的方法是相对应的:
impl<const ORDER: usize> LockedHeap<ORDER> {
/// Creates an empty heap
pub const fn new() -> Self {
LockedHeap(Mutex::new(Heap::<ORDER>::new()))
}
/// Creates an empty heap
pub const fn empty() -> Self {
LockedHeap(Mutex::new(Heap::<ORDER>::new()))
}
}
单看这里还看不出来,因为还套了一层
Heap
,要看
Heap
的获取实例的方法.
加互斥锁
理解了上边的语法,只需要理解
GlobalAlloc
这个
trait
对于
LockedHeap
的实现:
#[cfg(feature = "use_spin")]
unsafe impl<const ORDER: usize> GlobalAlloc for LockedHeap<ORDER> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
self.0
.lock()
.alloc(layout)
.ok()
.map_or(core::ptr::null_mut(), |allocation| allocation.as_ptr())
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
self.0.lock().dealloc(NonNull::new_unchecked(ptr), layout)
}
}
实际上就是在
Heap
外边加了一个
Mutex
互斥锁,那么对于
alloc
和
dealloc
的实现,只需要经过互斥锁访问里边的
Heap
,然后访问
Heap
的
alloc
和
dealloc
方法.
Heap
定义
Heap
实际上由一个长度为
ORDER
的
list
和
user
,
allocated
和
total
几个值组成.
pub struct Heap<const ORDER: usize> {
// buddy system with max order of `ORDER - 1`
free_list: [linked_list::LinkedList; ORDER],
// statistics
user: usize,
allocated: usize,
total: usize,
}
那么
ORDER
实际上就是
const 值泛型
了.
为什么在代码里不需要指定ORDER的值?
因为我们设置的包的版本为
0.6
,这个版本的包没用加入泛型参数,而是固定链表长度为
32
.
获取实例
查看
Heap
的
new
和
empty
方法:
impl<const ORDER: usize> Heap<ORDER> {
/// Create an empty heap
pub const fn new() -> Self {
Heap {
free_list: [linked_list::LinkedList::new(); ORDER],
user: 0,
allocated: 0,
total: 0,
}
}
/// Create an empty heap
pub const fn empty() -> Self {
Self::new()
}
}
这里注意
list
是一个
LinkedList
类型,是一个链表.
设置堆范围
记得上一篇博客内容,我们是使用如下代码初始化的:
/// Initialize heap allocator
pub fn init_heap() {
unsafe {
HEAP_ALLOCATOR
.lock()
.init(HEAP_SPACE.as_ptr() as usize, KERNEL_HEAP_SIZE);
}
}
这里
且不说
HEAP_ALLOCATOR.lock()
是怎么获取到
Heap
实例的.这里这句
init
确实是调用的
Heap
的
init
.
接下来我们看它的实现.
impl<const ORDER: usize> Heap<ORDER> {
... ...
/// Add a range of memory [start, end) to the heap
pub unsafe fn add_to_heap(&mut self, mut start: usize, mut end: usize) {
// avoid unaligned access on some platforms
start = (start + size_of::<usize>() - 1) & (!size_of::<usize>() + 1);
end &= !size_of::<usize>() + 1;
assert!(start <= end);
let mut total = 0;
let mut current_start = start;
while current_start + size_of::<usize>() <= end {
let lowbit = current_start & (!current_start + 1);
let mut size = min(lowbit, prev_power_of_two(end - current_start));
// If the order of size is larger than the max order,
// split it into smaller blocks.
let mut order = size.trailing_zeros() as usize;
if order > ORDER - 1 {
order = ORDER - 1;
size = 1 << order;
}
total += size;
self.free_list[order].push(current_start as *mut usize);
current_start += size;
}
self.total += total;
}
/// Add a range of memory [start, start+size) to the heap
pub unsafe fn init(&mut self, start: usize, size: usize) {
self.add_to_heap(start, start + size);
}
}
init
是调用的
add_to_heap
,输入的是
堆需要管理内存的初始地址和空间大小
.
主要是
add_to_heap
中精妙的算法.
地址对齐算法
对于
首地址
,要保证
start
的值是与
usize
的大小对齐的.
这里首先要声明,所有的变量大小都是
\(2^n\)
.那么它的二进制实际上是
某一位是1其余位都是0
的.
start = (start + size_of::<usize>() - 1) & (!size_of::<usize>() + 1);
Rust里
!
是按位取反,和C里边
!
是逻辑非
~
才是按位取反
不同
.
这里用的公式实际上是$$aligned_addr = (addr + align - 1) & (!align + 1)$$
这里直接举例说明.
本身不对齐的
addr
:
\(addr=15,align=2\)
\(addr=b'0\_1111\)
\(addr+align-1=b'1\_0000\)
\(align=b'0\_0010\)
\(!align=b'1\_1101\)
\(!align+1=b'1\_1110\)
\(aligned\_addr=b'1\_0000\)
最终得到的结果
aligned_addr
是16
本身已经对齐的
addr
:
\(addr=16,align=2\)
\(addr=b'1\_0000\)
\(addr+align-1=b'1\_0001\)
\(align=b'0\_0010\)
\(!align=b'1\_1101\)
\(!align+1=b'1\_1110\)
\(aligned\_addr=b'1\_0000\)
最终得到的结果
aligned_addr
是16
设
align
为
\(2^n\)
,
addr + align - 1
保证了如果低
n
位只要不是全
0
就都会向
n + 1
位进
1
,而右边
!(align-1)
,减
1
后按位取反,再做
与
运算保证低
n
位为
0
,这样就完成了对齐,且
如果不是对齐的向上取整
.
同样地,对于
尾地址
:
end &= !size_of::<usize>() + 1;
也写成公式表达:$$addr_aligned=addr&(!align+1)$$
这样就很好理解,保证低
n
位是
0
,这样也是一个对齐的地址,但是
向下取整
.
这样
首地址向上取整,尾地址向下取整
,就可以保证操作的地址是原地址的
子集
,不会出现越界.
#todo
这里可能需要画张图.
最后通过:
assert!(start <= end);
保证地址
有效
.
地址录入堆的算法
计算地址的对齐要求
根据
起始地址
计算地址要求是几字节对齐的,就是计算地址的
最低有效位
.
计算地址最低一位的
1
对应的值:
公式:$$lowbit=num&(!num+1)$$
例子:
\(num=10\)
\(num=b'1010\)
\(!num=b'0101\)
\(!num+1=b'0110\)
\(num\&(!num+1)=b'0010\)
\(lowbit=b'0010=2\)
对
num
取反,那么
最低位
的
1
变成
0
,其余的
0
都变成
1
,那么
!num+1
一定会使得最低位
1
变成
1
,其余位变回
0
,这样在与
num
自身
求与
,最终得到的就是只有
最低位1
的一个数.
计算剩余空间中能容纳的2的幂的大小
先说
计算小于或等于给定数
num
的最大 2 的幂
:
pub(crate) fn prev_power_of_two(num: usize) -> usize {
1 << (usize::BITS as usize - num.leading_zeros() as usize - 1)
}
usize::BITS
是
usize
的位数,
num.leading_zeros()
是
最高一位
1
之前的
0
的个数
.
那么求
usize::BITS as usize - num.leading_zeros() as usize - 1
就是第一个
1
以后的位数.
那么很容易明白最后求出来的就是
小于或等于给定数
num
的最大 2 的幂
.
计算块大小
比较
地址最低一位的
1
对应的值
和
小于或等于地址区间长度的最大2的幂
的大小,选择比较小的那一个.
这样理解,
- 正常情况下,最小的块大小应该是
符合地址对齐
的.- 但是可能
剩下的空间
不足以存下这样的块,这时候就按照剩余空间中能容纳的最小
\(2^n\)
的大小决定块的大小.
判断块大小和最大阶
计算当前阶数,
size
后有几个
0
就是几阶.
如果阶数大于最大阶,那么就把
块分半
,
降一阶
.
GPT:
Buddy System 算法有一个最大阶的概念。最大阶限制了单个块的最大大小。
内存碎片管理
:通过限制块的大小,可以更好地管理内存碎片。如果块太大,可能会导致内存碎片问题,因为大块可能无法被较小的请求完全利用。
性能优化
:较小的块更容易管理和分配,可以提高内存分配和释放的效率。
累积当前分好的块的大小
使用
total
计算此时使用的块的大小.
将块起始地址根据阶数存储在对应阶数的可用空间列表中
每个可用空间列表的
每个元素
是
一个链表
,链表保存
当前阶数
的起始地址.
也就是
同样大小的块的指针存在一个链表中
.
self.free_list[order].push(current_start as *mut usize);
移动起始地址指针
移动起始地址指针,使得下一轮继续分配.
current_start += size;
总结
可以看到是先将
可分配内存的地址对齐
,从
start
到
end
,
尽量
把空间分为
更大的
\(2^n\)
的块
,而不浪费空间,并且用链表存储起来.
具体怎么回事呢.
这里以最小对齐单元为
8=b1000=0x0008
为例.
例子一
比如你的地址是
(0x0100,0x0120)
,那么经过对齐之后
还
是
(0x0100,0x0120)
:
这里注意
0x0120-0x0100=32
,因此直接分配一个大小为
32
的块.
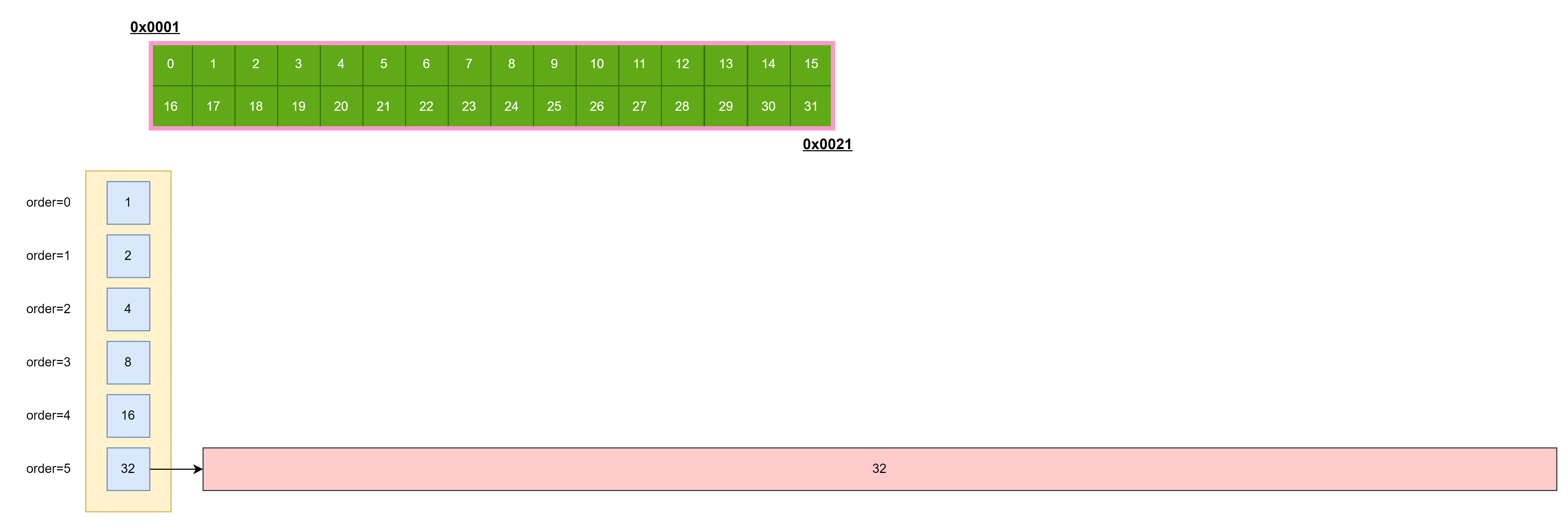
例子二
比如你的地址是
(0x0001,0x0021)
,那么经过对齐之后是
(0x0008,0x0021)
:
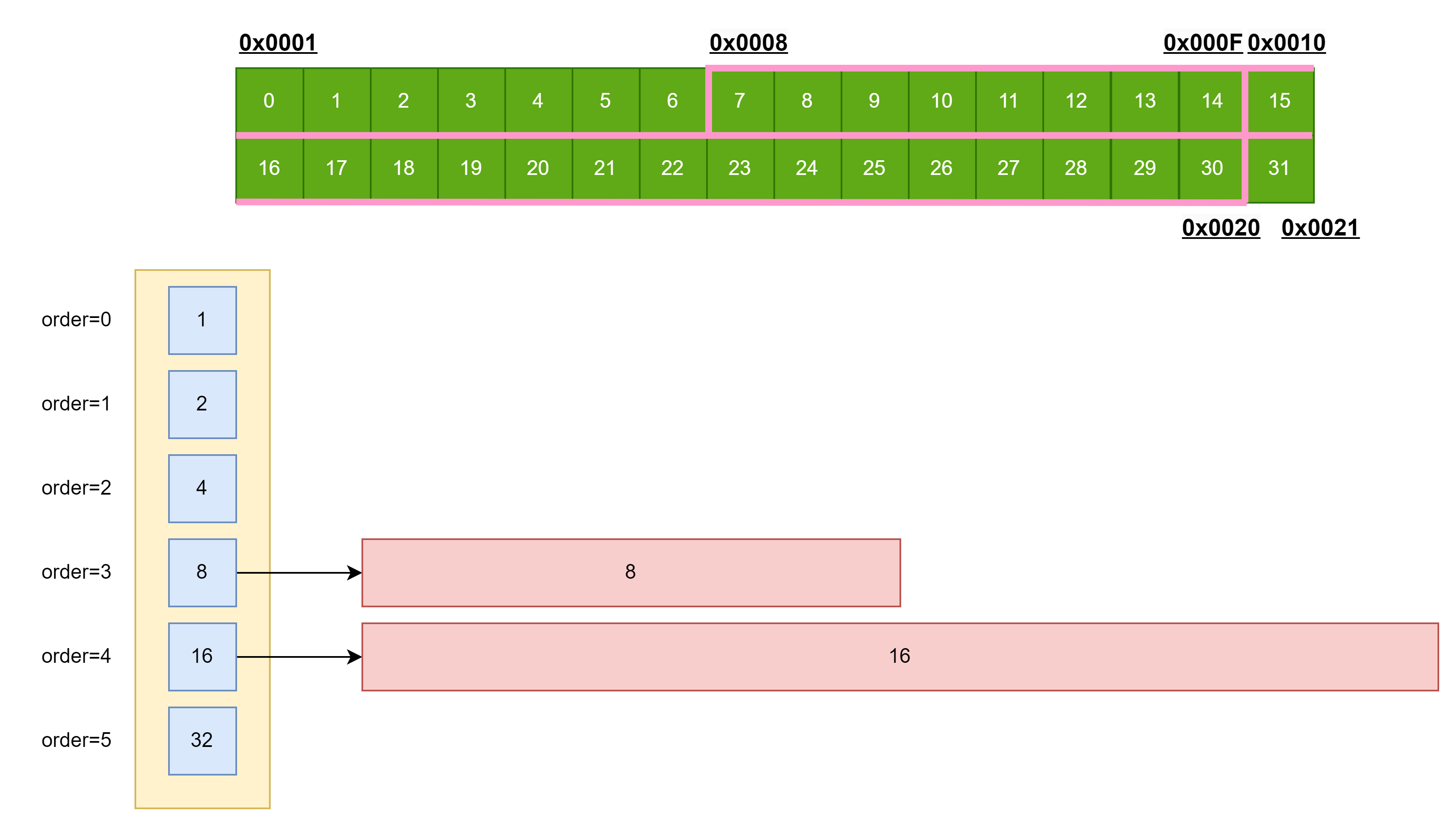
为了
物尽其用
,每次去对齐最低位.
到了最后,可能剩余的内存不足以满足对齐最低位了,这时候因为我们的
地址是对齐过
的,因此剩余的内存大小也是满足
\(2^n\)
的,直接把剩余内存存成一个块.
如果可分配的内存超过可用
空间列表
存储阶数,那么就分解,一直到能分配的最大块储存.
分配内存
分配内存的代码如下:
pub fn alloc(&mut self, layout: Layout) -> Result<NonNull<u8>, ()> {
let size = max(
layout.size().next_power_of_two(),
max(layout.align(), size_of::<usize>()),
);
let class = size.trailing_zeros() as usize;
for i in class..self.free_list.len() {
// Find the first non-empty size class
if !self.free_list[i].is_empty() {
// Split buffers
for j in (class + 1..i + 1).rev() {
if let Some(block) = self.free_list[j].pop() {
unsafe {
self.free_list[j - 1]
.push((block as usize + (1 << (j - 1))) as *mut usize);
self.free_list[j - 1].push(block);
}
} else {
return Err(());
}
}
let result = NonNull::new(
self.free_list[class]
.pop()
.expect("current block should have free space now")
as *mut u8,
);
if let Some(result) = result {
self.user += layout.size();
self.allocated += size;
return Ok(result);
} else {
return Err(());
}
}
}
Err(())
}
首先,传入的参数
layout
是一个结构体或者一个基本数据类型.
-
计算大于这个基本数据类型大小的
\(2^n\)
. - 计算这个基本数据类型的对齐大小.
-
计算
usize
的大小.
比较这三个大小,
选择其中最大
的作为
size
.
最后取
size
的
order
阶数为
class
,也就是实际上只找比
class
大的
order
对应链表中的未分配的块.
从最小---也就是最符合
size
大小的对应链表找起,如果是非空的就调出来.
此时匹配的
order
为
i
.
(class + 1..i + 1).rev()
是非常巧妙的设计,从
class+1
到
i+1
,并且
翻转
.
每次
pop
一个块,并且把这个块分成两个块,计算两个块的
首地址
,然后存进下一级的块.
一直到符合大小块的
class
.
最后只需要把当前
class
对应链表的第一个块
pop
出来即可,这就是答案.
销毁内存
销毁内存的方法为:
pub fn dealloc(&mut self, ptr: NonNull<u8>, layout: Layout) {
let size = max(
layout.size().next_power_of_two(),
max(layout.align(), size_of::<usize>()),
);
let class = size.trailing_zeros() as usize;
unsafe {
// Put back into free list
self.free_list[class].push(ptr.as_ptr() as *mut usize);
// Merge free buddy lists
let mut current_ptr = ptr.as_ptr() as usize;
let mut current_class = class;
while current_class < self.free_list.len() - 1 {
let buddy = current_ptr ^ (1 << current_class);
let mut flag = false;
for block in self.free_list[current_class].iter_mut() {
if block.value() as usize == buddy {
block.pop();
flag = true;
break;
}
}
// Free buddy found
if flag {
self.free_list[current_class].pop();
current_ptr = min(current_ptr, buddy);
current_class += 1;
self.free_list[current_class].push(current_ptr as *mut usize);
} else {
break;
}
}
}
self.user -= layout.size();
self.allocated -= size;
}
首先,传入的参数
ptr
是一个结构体或者一个基本数据类型的
指针
.
-
计算大于这个基本数据类型大小的
\(2^n\)
. - 计算这个基本数据类型的对齐大小.
-
计算
usize
的大小.
比较这三个大小,
选择其中最大
的作为
size
.
最后取
size
的
order
阶数为
class
,也就是实际上只找比
class
大的
order
对应链表中的未分配的块.
把
ptr
存入
可用空间列表
free_list
里边.
但是只是简单地存入,会导致
空间越来越碎片化
,这样后续申请大的内存块就无法提供.
这里有个非常核心的算法,也就是为啥这个算法叫
buddy system
.
let buddy = current_ptr ^ (1 << current_class);
是通过这种方法计算当前内存块的
buddy
.
1<<current_class
是求出一个二进制
只有一个位是
1
的
值.
随后
current_ptr
与它求
异或
,那么最后实际上求出的是对
current_ptr
在
class
那一位的
翻转
的结果.
假如是
current_ptr
是
000110100100
:
-
000110100100
(
current_ptr
) -
000000000100
(掩码) -
000110100000
(异或结果)
那么,实际上这两个地址是
相邻的两个同大小的块
.
如果在这个
class
对应的链表中找到这个地址开始的块,那么合并这两个块,然后找两个地址
较小
的,实际上是地址在前半边的,然后存入
order
大一级
的链表中.
Buddy System内存分配算法
看完代码感觉心里有底了,但是还是乱糟糟的,还是需要系统性地捋清一下算法.
实际上理论部分就是躲不过嘛,
不好好搞要吃大亏
!
这里通过
使用指定filetype的方法
找到了
很好的资料
.
链表
Rust刚接触的时候就听说链表难写,我看了仓库中链表相关的算法确实可以
看懂
,但是看懂和能够自己写出来是两码事.
要弄清楚三件事:
- 使用了rust的那些特性
- 为什么要用到这些特性
-
为什么要用
unsafe
#TODO
后续可能出一个自写rust链表的练习帖子.
总结
做事不要太工程化,尤其是
自学的过程
中,要注重基础注重能力的培养,
自我培养
的过程中要注意
基础
,要把
能跑就行
这种思想赶出脑子.
如果自学的时候还是能跑就行,那为什么还要自学呢?又没人给我发工资.





