使用Pytorch手把手搭建Transformer网络结构并完成一个小型翻译任务
来源:辣条科技站Gamer发布时间: 2024-10-13 10:31:26
在本文中,我们将手把手搭建一个Transformer网络结构,并使用PyTorch完成一个小型翻译任务。
首先,让我们来拆解Transformer结构。Transformer由编码器和解码器(Encoder-Decoder)组成。编码器由Multi-Head Attention和Feed-Forward Network组成的结构堆叠而成,而解码器由Multi-Head Attention、Multi-Head Attention和Feed-Forward Network组成的结构堆叠而成。
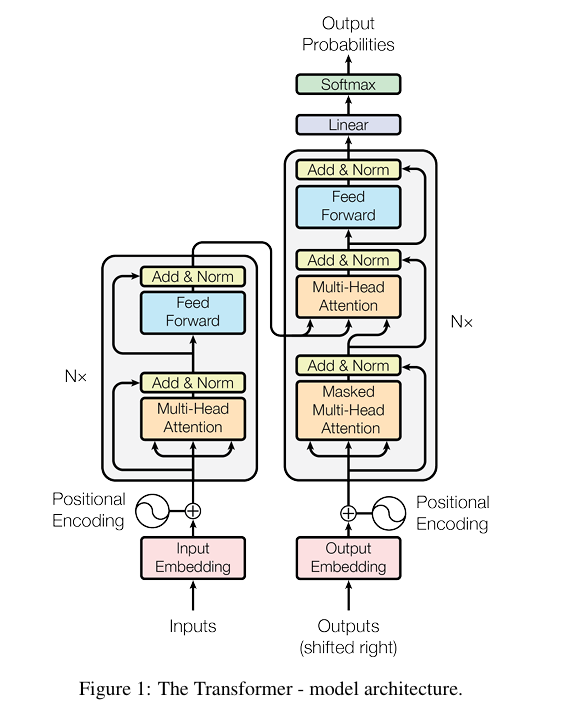
接下来,我们来看一下编码器(Encoder)和解码器(Decoder)的代码实现:
class Encoder(nn.Module):
...
class Decoder(nn.Module):
...
class Transformer(nn.Module):
...
接着,我们来看一下Multi-Head Attention的实现:
Multi-Head Attention包含多个Attention头,其计算过程如下:
- 对输入进行线性变换,得到QKV矩阵
- QK点积、缩放、softmax
- 再对V进行加权求和
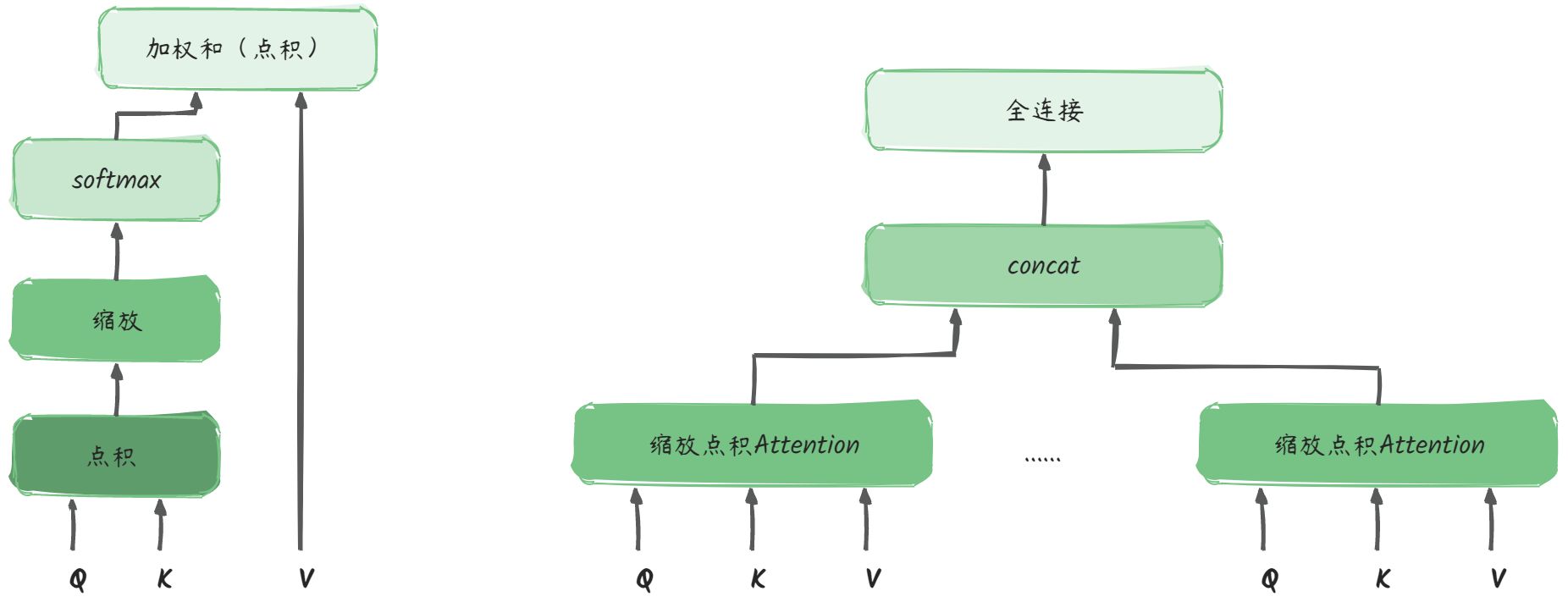
我们来手把手走一下Multi-Head Attention的计算:
假设输入序列的长度为n,针对每个token的编码长度为d,则输入为(n, d)
权重矩阵:$ W_Q: (d, d_q), W_K: (d, d_q), W_V:(d, d_v)
$
-
得到的QKV分别为:$ Q: (n, d_q), K: (n, d_q), V:(n, d_v)
$ - Q与K的转置相乘:$ Q \cdot K^T : (n, d_q) \cdot (d_q, n) = (n, n) $,每一个点的值代表第i个token和第j个token的相似度
- 缩放:不改变矩阵的尺寸,只改变矩阵中的值
- softmax:对矩阵中的值进行归一化
- 对V做加权求和:$ softmax(\frac {Q \cdot K^T} {\sqrt{d_k}})\cdot V = (n, n)\cdot(n, d_v) = (n, d_v) $
-
针对一个$ (n, d)
\(的输入,单头得到的输出为\)
(n, d_v)
\(, 多头concat得到的输出就是\)
(n_{heads}, n, d_v) $ - transpose并进行fully-connection运算: $ (n_{heads}, n, d) -> (n, n_{heads}*d_v) -> (n, d) $
class MultiHeadAttention(nn.Module):
...
接下来,我们来看一下Feed-Forward Network的实现:
在Encoder和Decoder的每个注意力层后面都会接一个Position-Wise Feed-Forward Network,起到进一步提取特征的作用。这个过程在输入序列上的每个位置都是独立完成的,不打乱,不整合,不循环,因此称为Position-Wise Feed-Forward。
计算公式为:$ F(x) = max(0, W_1x+b_1)*W_2+b_2 $
计算过程如图所示,使用conv1/fc先将输入序列映射到更高维度(d_ff是一个可调节的超参数,一般是4倍的d),然后再将映射后的序列降维到原始维度。

class PoswiseFeedForwardNet(nn.Module):
...
class PoswiseFeedForwardNet_fc(nn.Module):
...
以上是关于Transformer网络结构的搭建和Multi-Head Attention、Feed-Forward Network的实现。通过这些代码,我们可以深入了解Transformer的内部工作原理。
参考链接:GPT图解
热门推荐
-

像素英雄无尽跑酷游戏下载-像素英雄无尽跑酷安卓版下载v1.5
2022-12-27 09:05:24 -

大脑课堂手机版下载-大脑课堂APP下载v2.1.1
2023-02-14 15:06:54 -

丝瓜草莓秋葵脏下载www大全资源无限看:全新资源每日更新
2023-03-11 17:58:18 -

AI智绘APP下载,AI智绘特效相机APP官方版 v1.0.6.0
2023-04-19 08:32:31 -

笔声笔记app下载-笔声笔记在线云笔记安卓端免费下载v1.1.0-note
2023-05-19 07:11:02 -

火柴人狙击战游戏下载-火柴人狙击战安卓版射击游戏下载v1.0
2023-06-09 15:36:20
人气榜